2024欧洲杯(中国区)官网-登录入口这是由于它们出色的性能和小体积-2024欧洲杯(中国区)官网-登录入口

一、论断写在前边
使LLM与东说念主类偏好保捏一致变得越来越弥留。论文提议了逐渐平直偏好优化(sDPO),在这种次序中,论文以逐渐花样使用偏好数据,而不是一次性使用。论文展示了应用sDPO比DPO约略取得更高的H4分数。论文还通过比拟平均γπref,从警戒上展示了sDPO导致愈加对皆的参考模子。
那时,对更复杂的DPO数据集进行分段的最好计谋仍然是一个需要进一步探索的鸿沟。由于这些数据集的复杂性,这项任务尤其具有挑战性。同期,与大大批LLM接头相似,论文的斟酌资源也受到了适度。
二、论文的简短先容
2.1 论文的配景
LLM通过一个包括预锤真金不怕火、监督微协调对皆调优的锤真金不怕火过程,透顶调动了当然言语处理(NLP)鸿沟,其中后者用于确保模子的安全性和实用性。因此,强化学习时刻,如近端计谋优化(PPO)(Schulman等东说念主,2017年),尽管复杂,但在此对皆阶段至关弥留。
为了科罚LLM锤真金不怕火中强化学习的复杂性,平直偏好优化(direct preference optimization,DPO)以过甚他次序因其简短灵验而备受珍摄。DPO波及行使东说念主工或强东说念主工智能的判断来筹划偏好数据集,遴荐对问题的优选和被拒却的回复。这些数据集用于通过比拟优选和被拒却谜底的对数概率来锤真金不怕火LLM。但是,对于很是模子(如GPT-4),获取这些概率可能具有挑战性,因为它们不提供输入的对数概率。
因此,在大大批实质场景中,参考模子无为被成就为基础SFT模子,这是一种潜在偏好可能不一致的较弱替代决策。该参考模子在DPO中起到下限的作用,即目的模子被优化为至少与参考模子相似对皆。因此,论文合计,一个照旧愈加对皆的参考模子将为DPO锤真金不怕火提供更好的下限,这对于对皆调优是故意的。一种遴荐是行使照旧经过对皆调优的繁密开源模子。
需要严防的是,由于衰退此类对皆模子,或者消除对参考模子的适度会导致安全问题,上述作念法可能行欠亨。相背,论文提议了"逐渐DPO"(stepwise DPO),简称sDPO,在这种次序中,论文在进行DPO锤真金不怕火时以逐渐花样使用偏好数据集(或偏好数据集的子集)。前一样貌中的对皆模子被用作现时样貌的参考模子,这么就能行使到愈加对皆的参考模子(即更好的下限)。从警戒上看,论文展示了使用sDPO不错取得性能更好的最终对皆模子。
2.2 论文的次序
2.2.1 对于参考模子的初步接头
为了评估在DPO中使用高超对皆的参考模子的弥留性,论文在Mistral-7B-OpenOrca和OpenHermes2.5-Mistral-7B四肢SFT基础模子的情况下,使用Ultrafeedback数据集施行了DPO锤真金不怕火的初步实验,这是由于它们出色的性能和小体积。论文比拟了以下参考模子:i)SFT基础模子自身,与传统DPO成就调换;ii)SOLAR-0-70B,一个更大且性能更好的模子;iii)Intel-7B-DPO,一个照旧对皆的参考模子。散伙纪念在表1中。
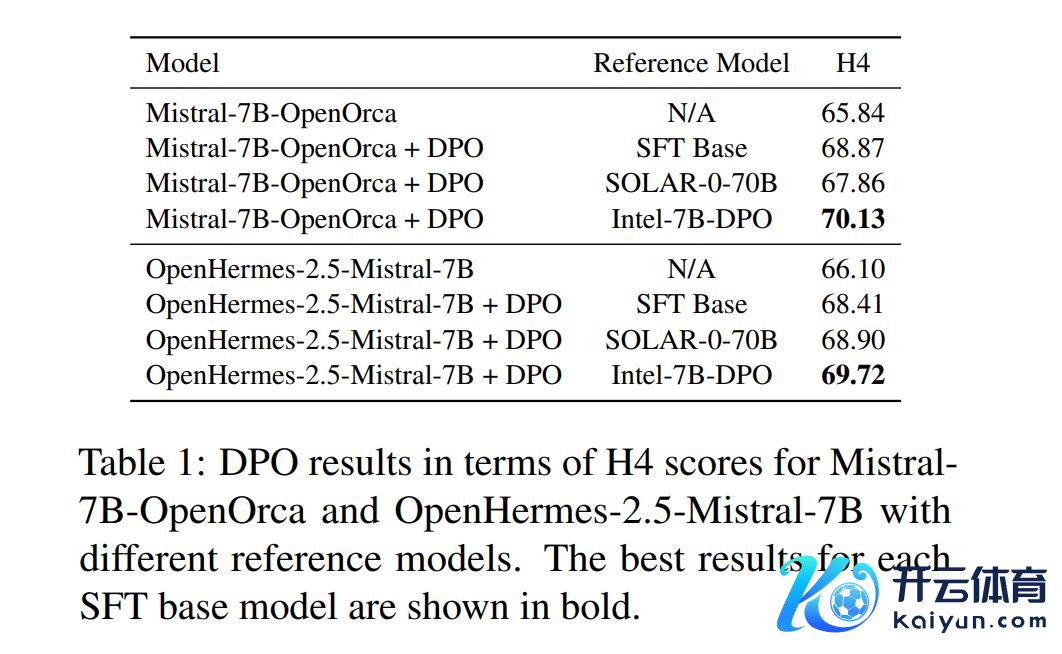
从表中不错看出,使用Intel-7B-DPO四肢参考模子会取得最好性能,甚而优于使用SOLAR-0-70B,后者是一个使用更大批据进行锤真金不怕火的大得多的模子。因此,参考模子是否事先对皆对最终对皆模子的性能起着弥留作用。苦处的是,由于时刻和安全问题,并不老是不错简短地使用开源预对皆模子四肢参考模子,即这种模子可能尚不存在或容易受到多样特定鸿沟的无益性和公说念性程序的影响。
为了科罚上述问题,论文提议了sDPO,它将愈加对皆的参考模子四肢锤真金不怕火框架的一部分。
2.2.2 逐渐DPO
在sDPO中,论文建议以逐渐花样使用可用的偏好数据集,而不是一次性使用。DPO和sDPO的合座经由对比如图1所示。
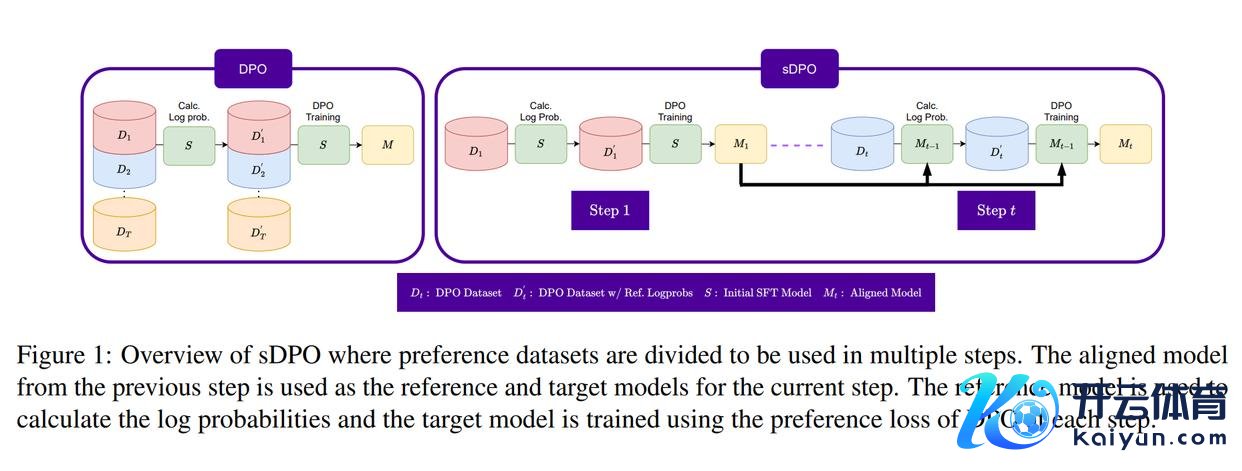
参考模子:参考模子用于斟酌偏好数据集的对数概率。对于每个样貌,只使用了总额据的一个子集,况且参考模子被启动化,即上一步的对皆模子。
目的模子:对于t>1,在sDPO的每个样貌中使用DPO的偏好亏本锤真金不怕火的目的模子也被启动化。这确保了使用sDPO锤真金不怕火的最终模子照旧平直使用了与使用DPO锤真金不怕火的模子调换数目的数据进行了锤真金不怕火。
直不雅解说:为了更深远地结伴sDPO,论文从(Rafailov等东说念主,2023年)再行胪列DPO亏本。
2.3 论文的后果
2.3.1 实验成就
锤真金不怕火细节:论文使用监督微调的SOLAR 10.7B四肢论文的SFT基础模子,因为它以其不同寻常的10.7B限制提供了出色的性能。此外,10.7B限制模子的稀缺导致衰退可四肢参考模子选择的开源模子,使得使用sDPO变得愈加必要。论文使用OpenOrca(约12K个样本)和Ultrafeedback Cleaned(约60K个样本)四肢论文的偏好数据集。锤真金不怕火超参数精致罢职Tunstall等东说念主(2023年)的成就。论文在sDPO中使用两个样貌,第一步使用OpenOrca四肢数据集D1,第二步使用Ultrafeedback Cleaned四肢数据集D2。
评估:论文行使HuggingFace怒放LLM名次榜(Beeching等东说念主,2023年)中的四项任务:ARC、HellaSWAG、MMLU、TruthfulQA。论文还汇报了这四项任务的平中分数,默示为H4。为了适度实验的复杂性,论文甩掉了Winogrande和GSM8K,即论文甩掉了生成任务,而只保留了多项遴荐任务。
2.3.2 主要散伙
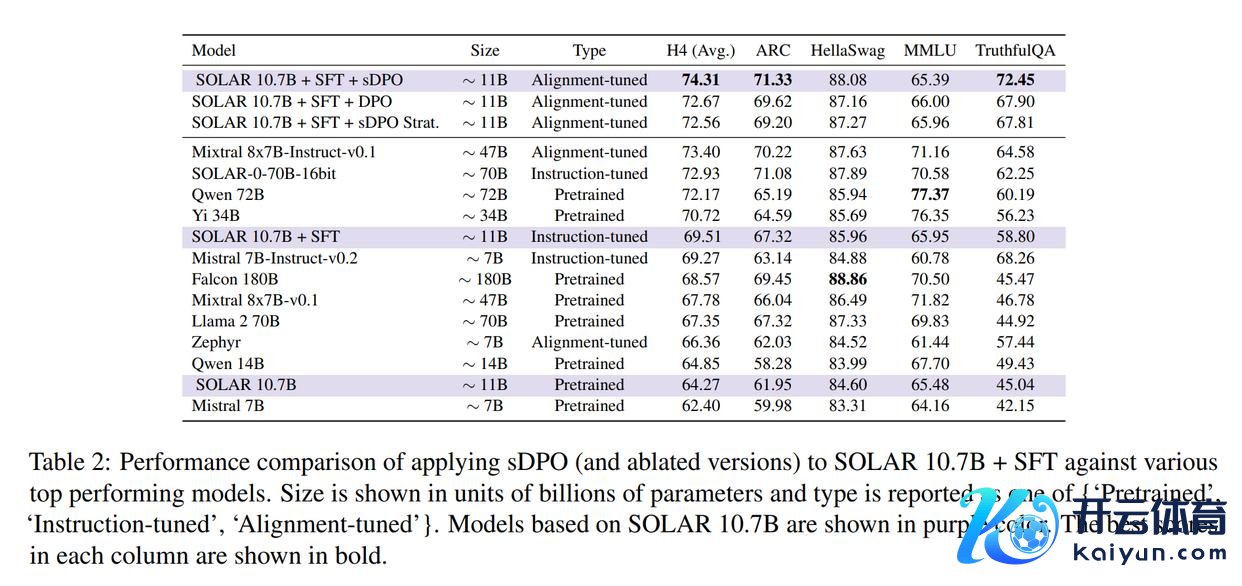
将sDPO应用于SFT基础模子的评估散伙以过甚他高性能模子的散伙如表2所示。将只进行预锤真金不怕火的"SOLAR 10.7B"与经过辅导调优的"SOLAR 10.7B + SFT"进行比拟,论文不错看到H4分数提高了+5.24。在SOLAR 10.7B + SFT上进一步应用sDPO将H4分数提高到74.31,擢升了+4.80。。这卓越标明,灵验的对皆调优可能是提高较小LLM性能的关键。此外,应用sDPO使TruthfulQA的分数大幅提高到72.45,这浮现了对皆调优过程的灵验性。
2.3.3 消融接头
论文还在表2中汇报了消融模子的评估散伙。"SOLAR 10.7B + SFT + DPO"一次性使用了通盘DPO数据,即D1 + D2,与传统DPO锤真金不怕火成就调换。"SOLAR 10.7B + SFT + sDPO Strat."使用分层抽样从OpenOrca和Ultrafeedback Cleaned的并麇集抽取约16.67%的数据点变成D1,并将剩余约83.33%用作D2,以模拟在SOLAR 10.7B + SFT + sDPO中使用的D1和D2的数据集大小。
比拟"SOLAR 10.7B + SFT + DPO"和"SOLAR 10.7B + SFT + sDPO",论文不错看到使用sDPO而不是DPO不错取得更高的合座H4分数,在ARC和TruthfulQA的分数上也有权臣提高。因此,论文合计sDPO不错四肢DPO锤真金不怕火的平直替代,带来更好的性能。不雅察"SOLAR 10.7B + SFT + sDPO"和"SOLAR 10.7B + SFT + sDPO Strat.",论文发现将可用DPO数据拆分为多个Dt的具体花样也会影响性能。论文发当今论文的实验中,使用不同的偏好数据集四肢Dt的当然拆分后果最好。
2.3.4 sDPO中的参考模子
sDPO在对皆调优方面的灵验性:论文通过比拟sDPO第1步和第2步中参考模子在Ultrafeedback Cleaned数据集上的平均γπref,即S和M1,从警戒上考证了上述情况,如图2所示。另一方面,使用来自sDPO第1步的对皆模子四肢参考模子时,平均值为-25.10,在对数程序上提高了13.50。
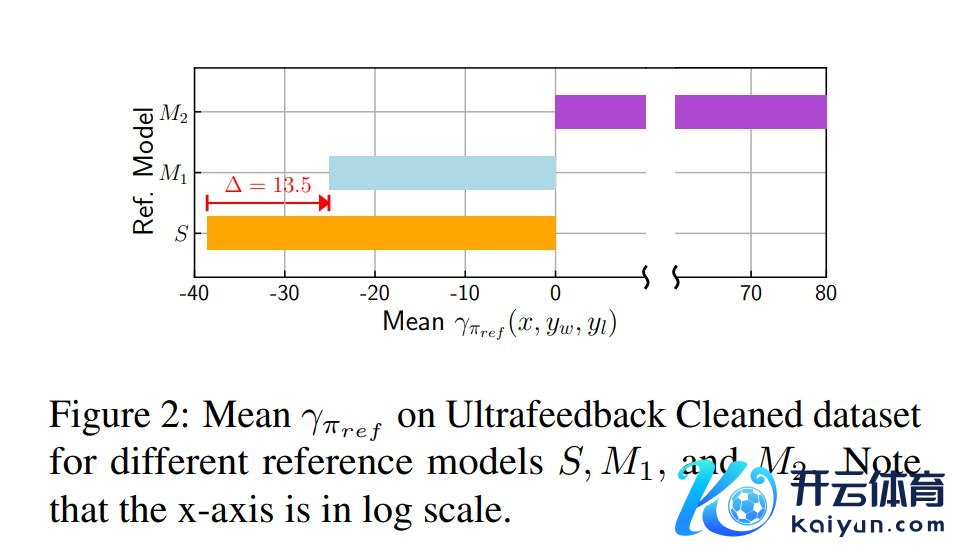
选择开源模子四肢参考模子可能是危境的:与S和M1不同,M2是在Ultrafeedback Cleaned数据集上锤真金不怕火的,即M2被用作了其照旧用于锤真金不怕火的数据的参考模子。请严防,当选择多样开源模子四肢参考模子时,这种情况可能常常发生。这是因为用于锤真金不怕火那些模子的数据集往往是不明晰的,况且可能不测中与偏好数据集肖似。M2的平均为84.35,远高于S或M1。M2值如斯之高,可能指向了M2对Ultrafeedback Cleaned数据集的过度拟合。这一散伙突显了仅选择开源模子四肢参考模子而不使用sDPO的潜在危境。
2.3.5 sDPO中的目的模子启动化
在sDPO的每一步中,目的模子亦然用上一步的对皆模子Mt-1启动化的。这确保了sDPO中的最终模子履历了与DPO中最终模子调换数目的数据锤真金不怕火。
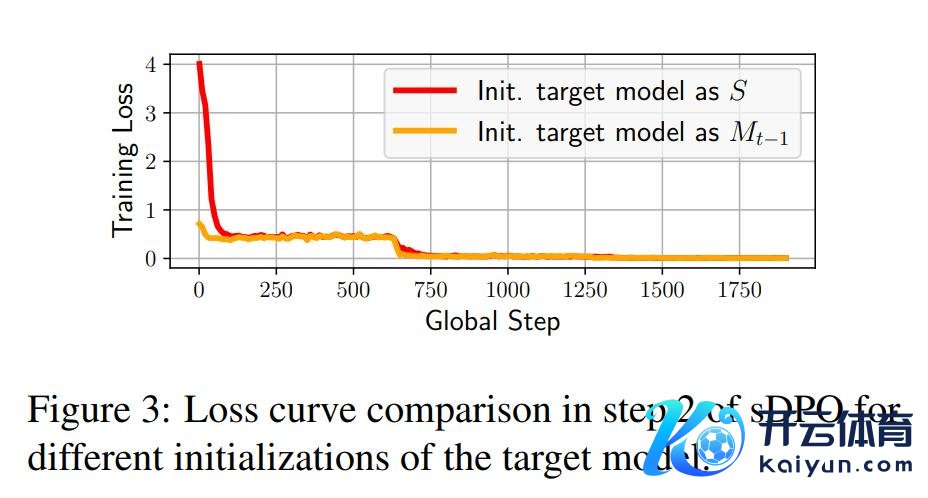
但是,如图3所示,将目的模子启动化为S会导致启动亏本比启动化大得多,这可能会导致不褂讪的锤真金不怕火。主要原因是DPO锤真金不怕火无为是在参考模子和目的模子调换的情况下进行的。
论文标题:sDPO: Don’t Use Your Data All at Once
论文集合:https://arxiv.org/pdf/2403.19270.pdf